
今回のIBM Think イベントに参加して明確になったのは、今後のITとビジネスの主戦場はAIとデータ分析であるということでした。もちろんこれまでもAIやデータの重要性は言われていましたが、Ginniの基調講演はもちろん個別セッションの数や熱気、そしてそこに参加する人の目の色が違いました。いわゆるDeveloperやData Scientist達から非常にSpecificな質問が繰り出されています。特にAIに関しては、IBM Watsonはもちろん、オープンソースのTensorFlowやCaffeといったものも適材適所で組み合わせて活用したり、高速な機械学習のためにGPUを使ったりするケースが増えてきており、後述の各ソリューションに関心が集まっていました。

全体的に同じ意見(by スピーカー&質問者)だったのは、あたり前ではありますが、AIにはデータが大事であること。上の資料にあるように、必要な量のデータが無ければAIにとってハシゴが無いのと同じ。あるセッションで「CxOの人は皆、AIがあれば何でも答えてくれると思っていて、データが必要ですと言っても取りあってくれない」と言ってそうだそうだと会場大ウケしていましたが、その様子からも世界共通なんだなぁと感じました。例えば以下のように、中心の機械学習(Machine Learning: ML)のコードに対して、周りでしなくてはいけないデータの管理や加工の方が面積は巨大で、機械学習なんて決まったエンジンを選んで学習させればよくて、問題はそこに突っ込むデータを作ったり、管理したり、機械学習で得られた結果のモデルを活用することだと語っていました。

ただ世界中の人が皆データが大事な事はわかっているんだけど、データをうまく管理できていない問題を抱えていることも分かりました。クラウドが増えているとはいえ、データの80%はまだ企業の中にあって有効に活用されていないと言われ、データを活用したいマーケティング部門やデジタル部門のデータ・サイエンティストがIT部門に依頼してもなかなかデータが出てこない・・・といった事象が話し合われていました。下図のように、パブリックなクラウドと、プライベートなクラウド、そして既存システムと企業のシステム構造が複雑になってきてデータが分散しているのも一因ではと思いました。
そこでIBMが出してきたのが、IBM Cloud Private (ICP) for DataとIBM Watson Studio。クラウドとオンプレも含めデータ(ファイル、DB含め)をカタログ化し管理するICP for Dataと、そのデータをAIや分析エンジンを使って実際に分析の実装をする際に使うWatson Studioです。ICP for Dataの概要は、Thinkの日本人用共有セッションでまとめられていたように以下になります。

ICP for Dataのアーキテクチャは以下ですが、肝は下のEnterprise Data Catalog。パブリックなクラウドのデータも、オンプレのプライベート・クラウドも既存システムも、一元的にデータの場所を管理できます。そして分散されたファイルやDBのデータから、AIの学習などに必要なデータを適切に取り出し、成型することができます。

これらの話は、上の右下にいるIBM AnalyticsのGM、Rob Thomasさんが分かりやすく話してくれました。
ICP for Dataでデータを管理・成型し、AI Readyにしたら、次はそれらのデータを利用してAIに学習させます。そのAI構築のための、統合分析・開発環境が「Watson Studio」です。
Watson Studioは以下のように、様々なデータを活用しながらWatsonを学習させるために使う統合AI開発ツールです。例えば追加で自分で大量の画像データをWatson Visual Recognition (VR)に学習させる際に、データを容易に取得し、どこまでデータを学習させたかも管理してくれます。また、Watson Machine Learning (機械学習)や、Deep Learning (深層学習)する際にも、学習させたデータも合わせて管理できます。もちろん先ほどのICP for DataのCatalogとも連携ができます。クラウド上のWatson APIとも自在に連携可能です。

Watson Studioは以下の右下の、IBM Watson Data & AIのGM、Beth Smithさんが紹介してくれました。構造化データ(DB等)と非構造化データ(画像、音、文書など)の両方を賢く検索したり準備したりでき、それを機械学習や深層学習させたモデルも管理するのに最適であると話してくれました。上の方の画像にあった、ML (機械学習)のコードなんてちょっとで、その周りのデータをどうするかの方がよっぽど手間がかかるのである・・・の周りのデータ全体をうまく管理してくれるツールですね。

最近のIBM製品の特徴ですが、以下のようにWatsonだけでなく、惜しげもなく主要なオープンソースもたくさんサポートしています。特に主流になりそうなのは、Spark、TensorFlow、Caffe、RなどのエンジンとJupiter Notebookです。基盤もオープンなDockerコンテナ、Kubernetes、NVIDIAのGPUもサポートしています。もちろん、Watsonをはじめ、SPSS Modelerなどの既存のIBMソリューションも対応しています。
改めてWatsonのようなAIでの学習を実施するには、データの管理が重要であることを認識しました。Bethの話にもありましたが、以下のように深層学習などの一つのニューラル・ネットワークを使えるものにするためには、数千のトレーニングを実施しないといけないからです。

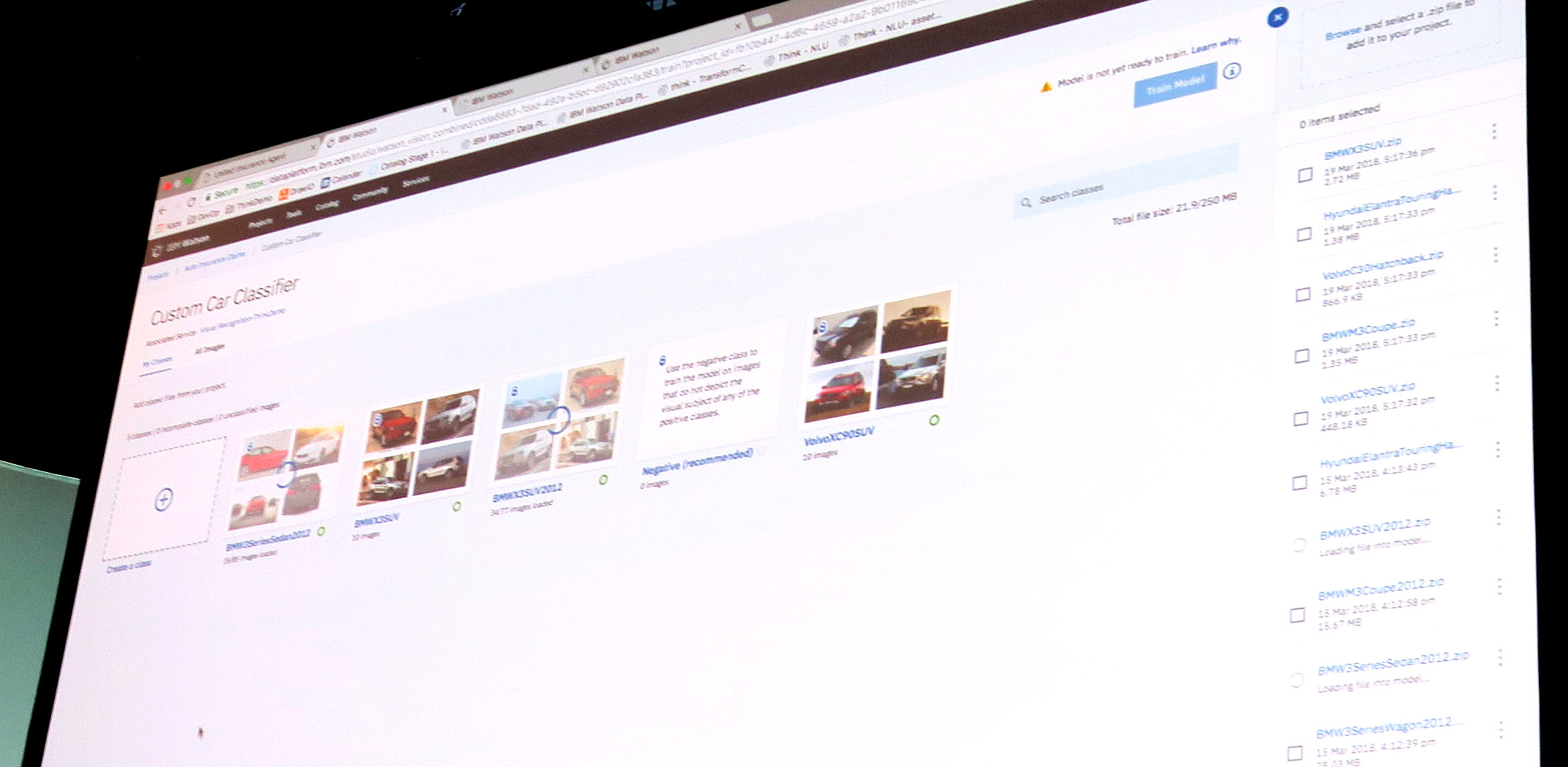
ではWatson Studioはどのように使うのか、というデモを見せてくれました。以下は車の保険のデモで、事故をした人が送ってきた車の画像がその人の車かどうかを判定するアプリです。以下のように事故車の画像とその車の持ち主の人の情報が表示されています。まずこの画像分析をする人 (データ・サイエンティスト)は、こういった車の画像やDBの中の個人情報をあまり意識しなくても (IT部門に依頼しなくても)カタログから迅速に取得ができます。またその際、データ分析に必要の無い個人情報は自動的にマスク (サニタイズ)して実際は誰か分からなく加工してあります。
その画像分析を実施した時に、何か気になることがあってこれまでWatsonがどの車の画像を学習したかを知りたければ、以下のようにそれぞれのWatson VRが今どの画像を追加で学習していたかを簡単に取り出すことができます。だいたいこういったソースのファイルなどは大量かつ分散していた、どこまで学習させたか自分でも分からなくなってしまうので助かりますよね。
このようなDeep Learningで画像をWatsonに学習させたりする際に、Watson Studioでは学習フローを以下のように「ニューラル・ネットワーク・モデラー」でビジュアルに作成することができます。会場のデモでは、一度学習フローを描いてから、繰り返しの部分をコピペで何度もコピーして見せてくれました。
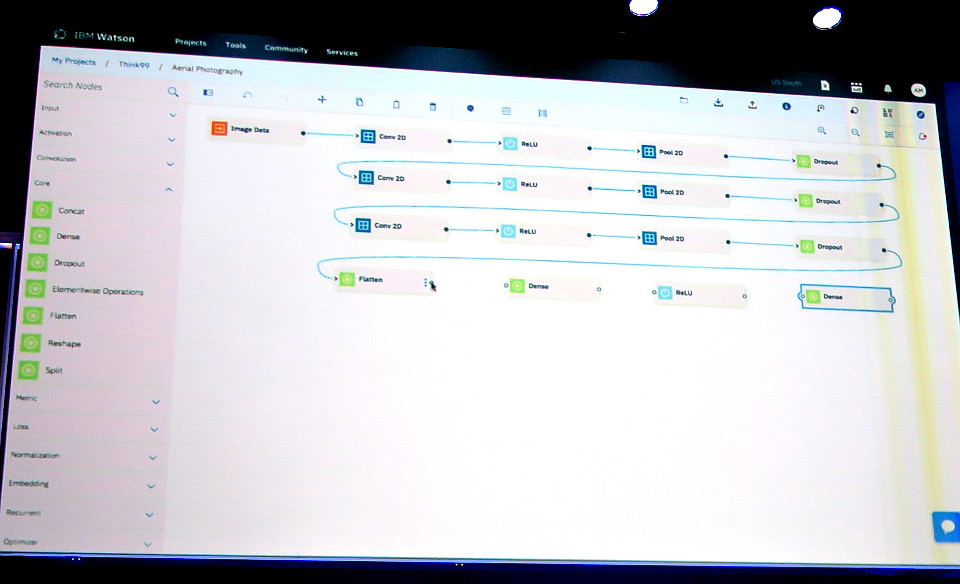
また以下のようにトレーニング情報をリアルタイムでモニタリングしたり、計算結果のモデルごとにそのパフォーマンスを比較したり、そういったチェックも容易にできます。

このツールはデータサイエンティストだけではなく、業務エキスパートや、データ技術者、開発者(The Developer)全員に使いやすくなる工夫がしてあるとのことでした。

そのBethのシアター・スピーチの最後に、なんと我等が日本のフォーラムエンジニアリングさんが、以下のように登壇いただきました!なかなかこういった大きな場に日本のお客様が登壇されることは多くないので、勝手ながら大変誇らしく思いました。

フォーラムエンジニアリングさんの話もやはり、AIには大量のデータが必要で、自分にぴったりな転職先を探すのに人手では限界があるため、Watsonの力を借りて効率化しているとのことでした。

別のAI事例セッションで面白かったのは、レッドブルさんの事例です。以下のF1などのレースカーの情報を大量に取得して、レースに勝てるように分析しているそうです。昨年のホンダさんのF1事例と似ていますが、こちらはスペクトラムというIBM製品を使っていました。

ちなみに上の、ML (機械学習)コードなんて全体のデータに必要な処理に比べたらかなり小さいもので・・・というのは、このレッドブルさんの事例で話されたものです。以下のようにIBM Power Systemsのサーバーの上で、LinuxとDockerコンテナを動かし、その上でIBM PowerAIという様々なAIソリューションが一つにパッケージされた製品を使っています。具体的なソフトウェアとしては、Spark、ANACONDA、TensorFlow、Caffeを使っていました。

その基盤としてIBM Spectrum Conductorという製品を使い、データの準備から、モデルのトレーニング、結果の表示など一元的に管理しています。Power AIなので、基調講演でも発表のあった、Power + GPU (NVIDIA)のパワーが発揮できますね。通常のCPUよりも、50倍速いという測定結果もあると話していました。
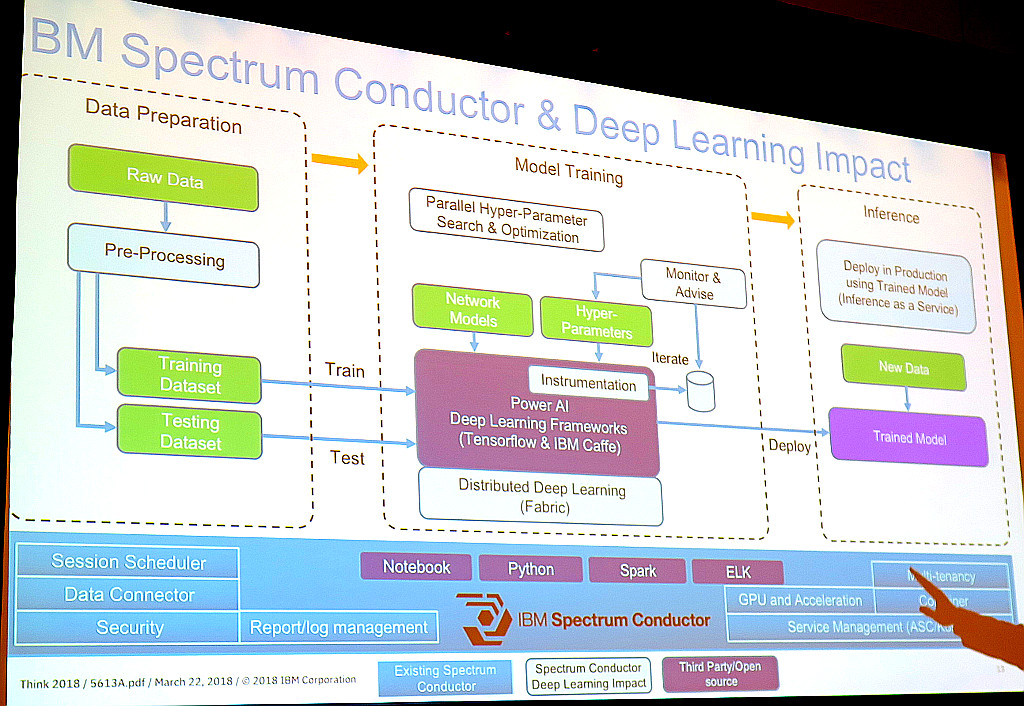
これと同様に、IBM CloudやCloud Privateも含めて管理してくれるのが、ICP for Dataですね。
あと、GinniとDavid Kennyの基調講演で発表のあった「IBM Watson Services for Core ML」。Watson Visual Recognitionで学習させたML(機械学習)モデルを、iPhoneのスマホの中にあるCoreMLで動かす事ができる機能は素晴らしいですね。クラウドにデータを上げなくても、iPhone端末の中で画像分析できるため、製造業の現場や金融系の出先で活躍しそうです。

全体を通した印象としては、ビジネスで使えるAI系のエンジンそのものは、Watson、Spark、Caffe、TensorFlowなどとメインのツールが出揃ってきたため、それらを有効に活用するために、学習のための大量データの管理をいかに効率的にするかが、これからの最重要課題と改めて認識しました。何だか急に闇雲に、機械学習をしたい気分になってきました!
⇒ IBM Think 2018 – Ginni会長による基調講演
⇒ IBM Think 2018 – イベントで見えたIBM Cloudの方向性
⇒ IBM Think 2018 – Blockchainの使い方が広がる