今回のIBM Think イベントに参加して明確になったのは、今後のITとビジネスの主戦場はAIとデータ分析であるということでした。もちろんこれまでもAIやデータの重要性は言われていましたが、Ginniの基調講演はもちろん個別セッションの数や熱気、そしてそこに参加する人の目の色が違いました。いわゆるDeveloperやData Scientist達から非常にSpecificな質問が繰り出されています。特にAIに関しては、IBM Watsonはもちろん、オープンソースのTensorFlowやCaffeといったものも適材適所で組み合わせて活用したり、高速な機械学習のためにGPUを使ったりするケースが増えてきており、後述の各ソリューションに関心が集まっていました。

全体的に同じ意見(by スピーカー&質問者)だったのは、あたり前ではありますが、AIにはデータが大事であること。上の資料にあるように、必要な量のデータが無ければAIにとってハシゴが無いのと同じ。あるセッションで「CxOの人は皆、AIがあれば何でも答えてくれると思っていて、データが必要ですと言っても取りあってくれない」と言ってそうだそうだと会場大ウケしていましたが、その様子からも世界共通なんだなぁと感じました。例えば以下のように、中心の機械学習(Machine Learning: ML)のコードに対して、周りでしなくてはいけないデータの管理や加工の方が面積は巨大で、機械学習なんて決まったエンジンを選んで学習させればよくて、問題はそこに突っ込むデータを作ったり、管理したり、機械学習で得られた結果のモデルを活用することだと語っていました。

ただ世界中の人が皆データが大事な事はわかっているんだけど、データをうまく管理できていない問題を抱えていることも分かりました。クラウドが増えているとはいえ、データの80%はまだ企業の中にあって有効に活用されていないと言われ、データを活用したいマーケティング部門やデジタル部門のデータ・サイエンティストがIT部門に依頼してもなかなかデータが出てこない・・・といった事象が話し合われていました。下図のように、パブリックなクラウドと、プライベートなクラウド、そして既存システムと企業のシステム構造が複雑になってきてデータが分散しているのも一因ではと思いました。
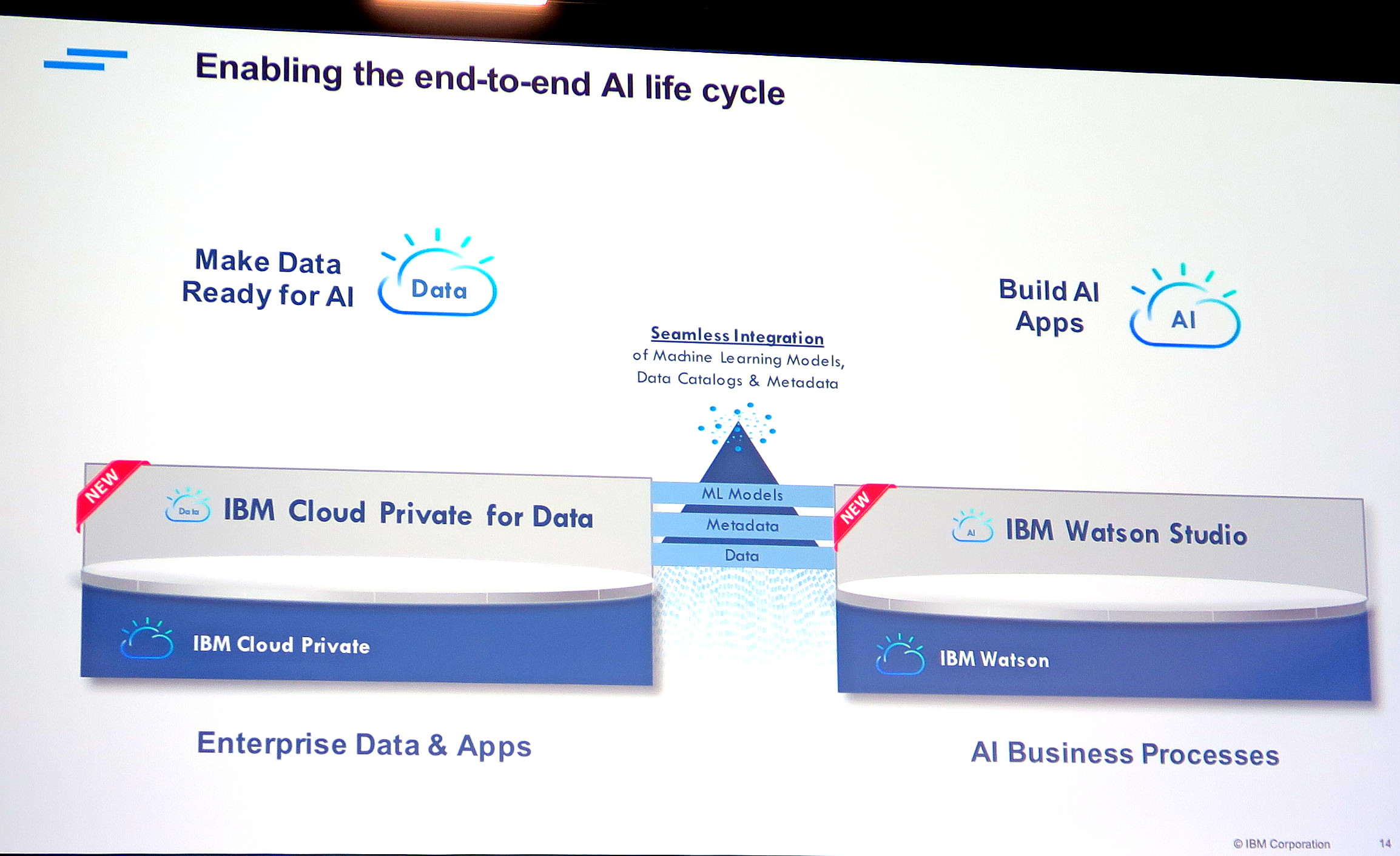
そこでIBMが出してきたのが、IBM Cloud Private (ICP) for DataとIBM Watson Studio。クラウドとオンプレも含めデータ(ファイル、DB含め)をカタログ化し管理するICP for Dataと、そのデータをAIや分析エンジンを使って実際に分析の実装をする際に使うWatson Studioです。ICP for Dataの概要は、Thinkの日本人用共有セッションでまとめられていたように以下になります。

ICP for Dataのアーキテクチャは以下ですが、肝は下のEnterprise Data Catalog。パブリックなクラウドのデータも、オンプレのプライベート・クラウドも既存システムも、一元的にデータの場所を管理できます。そして分散されたファイルやDBのデータから、AIの学習などに必要なデータを適切に取り出し、成型することができます。

これらの話は、上の右下にいるIBM AnalyticsのGM、Rob Thomasさんが分かりやすく話してくれました。
ICP for Dataでデータを管理・成型し、AI Readyにしたら、次はそれらのデータを利用してAIに学習させます。そのAI構築のための、統合分析・開発環境が「Watson Studio」です。