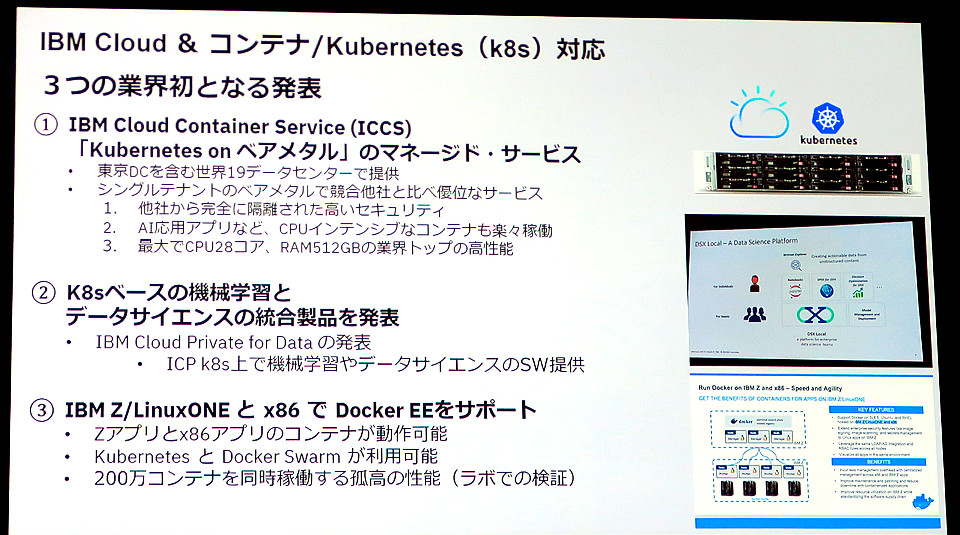
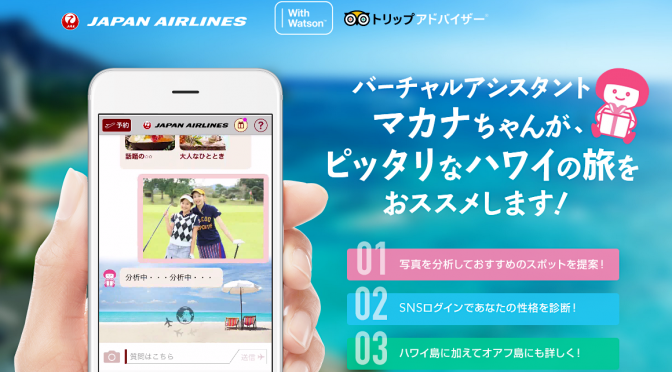
最近よく 「クラウドネイティブでの開発とは?」 とか 「マイクロサービス開発のポイントは?」 ときかれるため、先日講演した内容についてご紹介します。クラウドの活用が広がり、その最適な開発方法に関心が高くなってきていますね。
クラウド・ネイティブとは
クラウド・ネイティブな開発とは、つまりクラウドで動かすのに最適化されたアプリを開発する事。通常のアプリ開発とどこが違うのでしょうか?クラウド・ネイティブなソフトウェア開発を推進している団体、「クラウド・ネイティブ・コンピューティング・ファンデーション (CNCF)」 で確認してみましょう。

以下のリンク先にあるように主要なクラウド企業はほとんど参加し、様々な推進活動が実施されています。
では、クラウド・ネイティブの定義は何でしょうか?
このCNCFのホームページの以下のFAQに 「What is Cloud Native?」 が分かりやすく記述されています。
要約しますと、以下のように書かれています。
「クラウド・ネイティブ技術は、パブリックやプライベートもしくはそのハイブリッドなクラウドの新しいダイナミックな環境において、スケーラブルなアプリケーションの構築と稼働を実現します。コンテナーやサービス・メッシュ、イミュータブル・インフラストラクチャー、マイクロサービスがその典型的なアプローチです。
これらの手法によって、対障害性があり管理され可視化された、疎結合なシステムを可能にします。オートメーションと組み合わせることで、エンジニアは頻繁な変更を最小限の労力で可能になります。
CNCFはこの新しいパラダイムの適用を、オープンソースのエコシステムとベンダー・ニュートラルな製品により推進します。」
はじめての人には少し分かりにくいと思いますので、私なりに補足して解説します。まずクラウド・ネイティブ技術の適用環境ですが以下ように図で表してみました。

上記にありますように、クラウド・ネイティブなアプリケーションとは主に、Dockerなどの「コンテナ」化されており、Kubernetesなどの「動的オーケストレーション」技術で動的に構成される、「マイクロサービス」化されたアプリケーションが典型的と言われています。これはCNCFホームページの「What is CNCF?」にも書かれています。これらは現在のクラウドを支える主要な技術なので後でじっくり記述します。
その前に大切なのは、「What is Cloud Native?」にあるように、これらのクラウド・ネイティブ技術は、いわゆるパブリックのクラウドのためだけにあるわけではないという事です。クラウド・ネイティブなのにクラウドだけでないというのはやや逆説的ですが、コンテナやオーケストレーションはサーバーを迅速かつ柔軟に構成するためのたいへん優れた技術であるため、パブリック・クラウドだけでなく、オンプレのプライベート・クラウドでの活用も盛んになっています。オンプレであっても、クラウド技術を活用したいというユーザーが増えているためです。その事で、今はパブリック・クラウドでは不安があるアプリケーションも、まずはオンプレのプライベート・クラウドで稼働させてから後からそのコンテナをパブリックにそのまま展開する・・・といった自由な選択が後から可能になります。
クラウド・ネイティブ技術
では、その他の主なクラウド・ネイティブ技術を以下に紹介します。
【コンテナ化】
アプリなどの各要素をLinuxコンテナとしてパッケージすることで、再現性・透過性・環境独立性を実現します。Docker社のコンテナが主流で、既に様々なクラウド環境でサポートされています。特徴は、従来の仮想化と異なり、パッケージの中にLinux OSを含まないため軽量(サイズが小さい)で迅速なサーバー立ち上げが可能です。
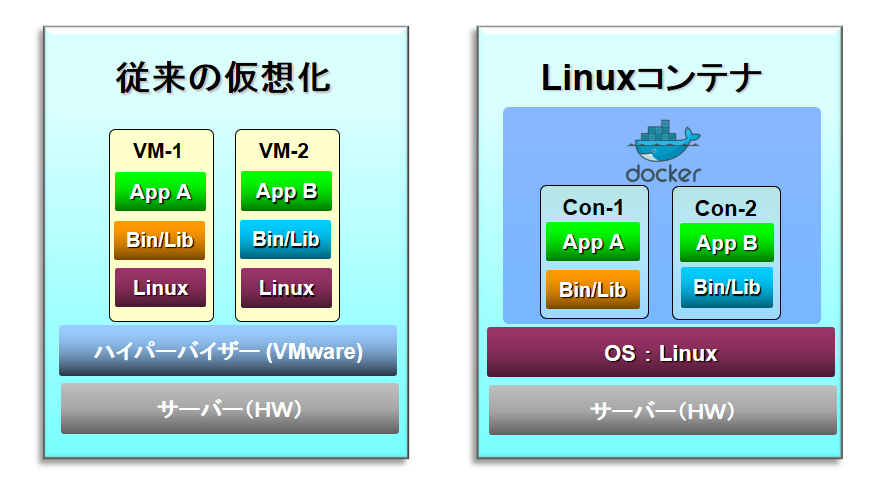
【動的オーケストレーション】
コンテナの複数サーバー(クラスタ)への配置を自動的にスケジュールし、リソースの活用を最適化します。主流はオープンソースのKubernetesで、元々はGoogle社が自社の膨大なクラスタを管理するために作成したもので、現在は多くの企業が開発に参画しています。
【API】
APIは、アプリケーションの対外インターフェースであり、従来のライブラリのAPIと区別するために、Web APIと呼ばれることもあります。通常のWebのプロトコルであるhttpでデータを通信する「REST」に、「JSON」と呼ばれるデータ形式でやり取りします。
【サービス・メッシュ】
アプリケーションが、後述のマイクロサービスで細分化され、多くのAPIでやり取りされるようになると、n対nの膨大なメッシュができ、さらにそのバージョンを区別したいと思うと管理が複雑になります。このようなサービスのメッシュの管理を容易にするサービス・メッシュが必要になります。その主流はGoogleやIBMなどが開発している「Istio」です。
【イミュータブル・インフラストラクチャー】
直訳すると、変えないインフラという意味ですが、いわゆる塩漬けでそのまま使い続けるという意味ではありません。本番のインフラに対して継続して様々な設定を変更したり、パッチを当てたりすると再現困難な環境になる事があります。現在動いている本番環境に変更を加え新しい本番環境を作りこんでいくのではなく、例えば新しい本番環境をイチから構築し、そちら側にサーバーをスイッチしていくようなイメージの方式です。
これらのクラウド・ネイティブ技術は、従来のシステム構築のパラダイムをシフトさせるべくクラウド環境から発展してきました。が、そういった優れたテクノロジーをオンプレ環境で使わない手はないため、今ではオンプレでも共通的に使われるようになっています。
マイクロサービス
クラウド・ネイティブの技術、最後は「マイクロサービス」です。マイクロサービスは、技術というよりは設計手法になります。細かくサービスを分割するマイクロサービスに対し、対極にあるのは「モノリシック」です。従来のアプリケーションでは、様々な機能が一つのモジュールに固められ、そこからアクセスするデータも複雑にからみあった大きな一枚岩になっているものもあります。しかし、機能同士が密結合になっているため、頻繁に変更を繰り返す顧客接点のアプリなどではビジネスのスピードについていけないケースがありました。マイクロサービスではこれを細かい単位に細分化することで防ごうという設計コンセプトです。
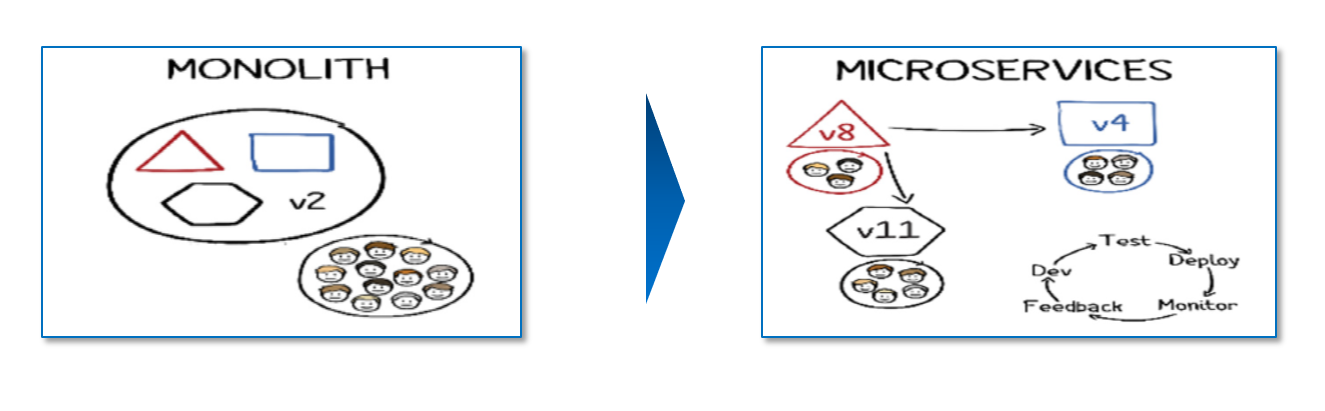
マイクロサービスでは、一つ一つのコンポーネントの単位を疎結合にすることで、個々のバージョンアップや問題の修正を容易にします。これまでモノリシックでは、一つの機能を変えるのに全体の機能を再テストが必要になる可能性がありましたが、マイクロサービスはそれぞれを独立させることで、影響を最小限にします。
特に以下のようにアプリとデータをセットで分割し、それを複数のサーバーで立ち上げることで、問題の所在を局所化させ、個別の更新を容易にします。マイクロサービスの中の機能が直接他の機能を呼び出すと密結合になってしまいますので、基本的にサービスはAPIを介して呼び出します。
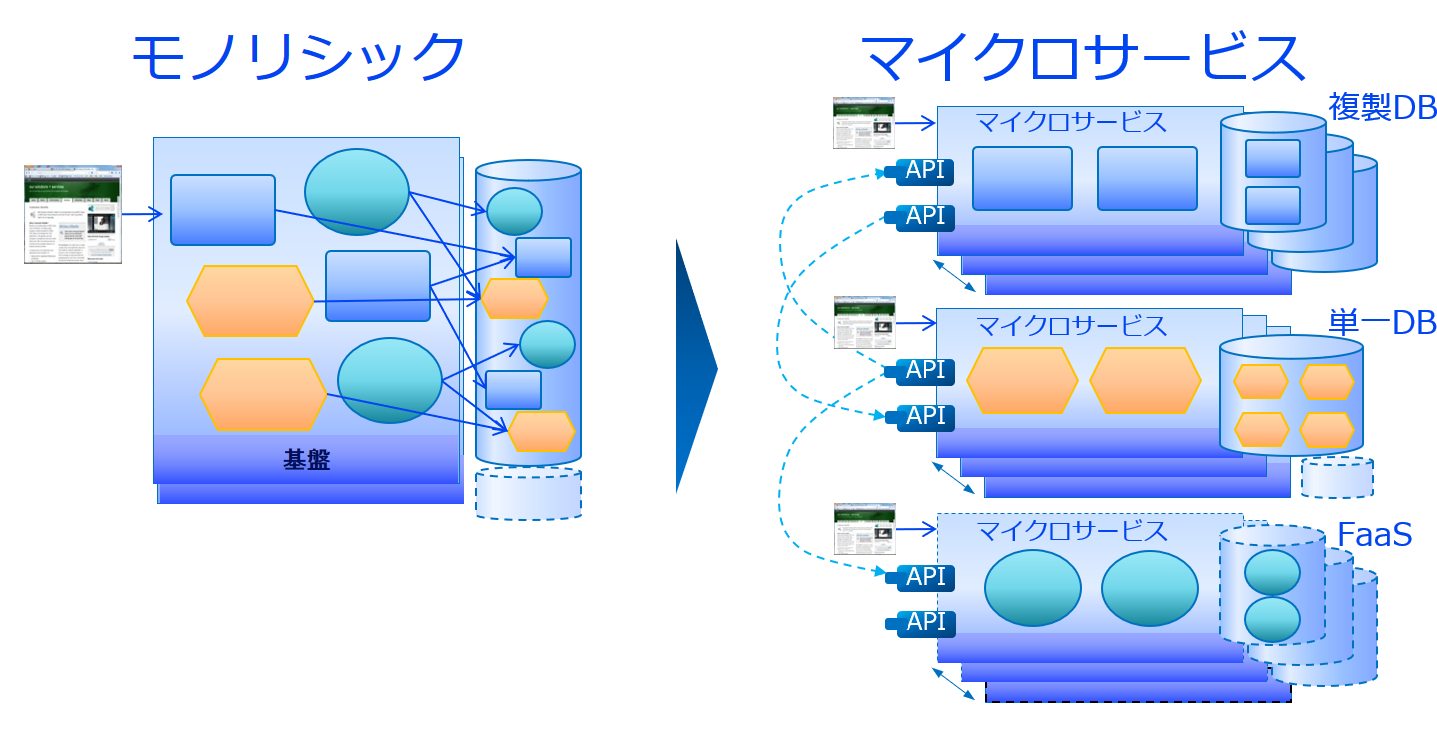
このことで、個々の機能のバージョンアップをする際や、問題が起こった際に修正を適用する際などに、全体に影響が派生せず個々のマイクロサービスの更新で済むため維持・運用が容易になります。
このマイクロサービスの設計の考え方は実は以前のSOAの経験を生かしてモダナイズする形で作られています。SOAは企業内のシステムを疎結合化し、ESBと呼ばれるバスで接続する形態でした。マイクロサービスは、特に顧客接点などのインターネット上のアプリに着目し、よりクイックにサービスを構築、より頻繁な更新が可能になるように考えられています。が、これまでのSOAでの設計経験が生かせる方式でもあります。